publications
2026
-
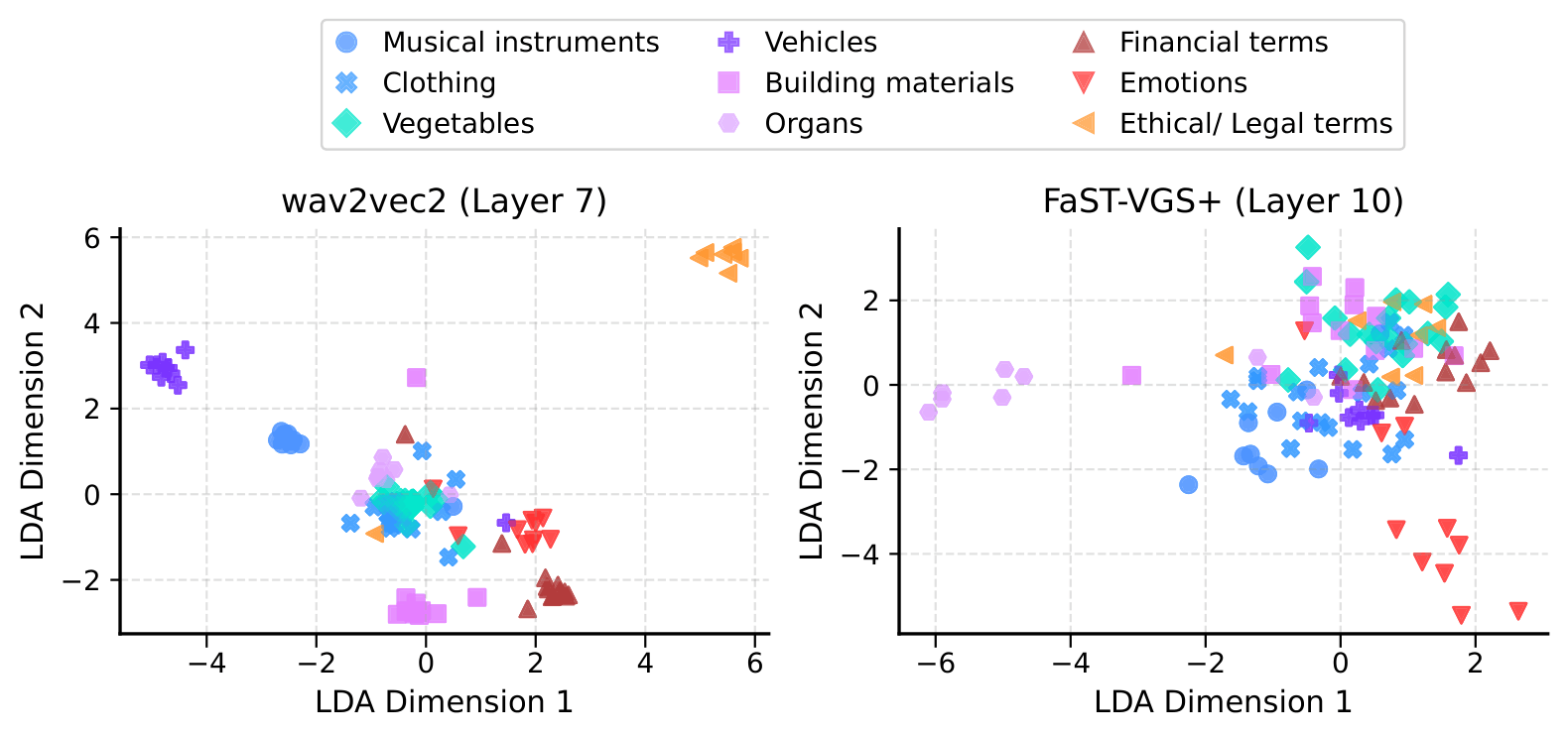 The Curious Case of Visual Grounding: Different Effects for Speech-and Text-Based Language EncodersAdrian Sauter, Willem Zuidema , and Marianne De Heer KlootsIn ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2026
The Curious Case of Visual Grounding: Different Effects for Speech-and Text-Based Language EncodersAdrian Sauter, Willem Zuidema , and Marianne De Heer KlootsIn ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2026How does visual information included in training affect language processing in audio- and text-based deep learning models? We explore how such visual grounding affects model-internal representations of words, and find substantially different effects in speech-vs. text-based language encoders. Firstly, global representational comparisons reveal that visual grounding increases alignment between representations of spoken and written language, but this effect seems mainly driven by enhanced encoding of word identity rather than meaning. We then apply targeted clustering analyses to probe for phonetic vs. semantic discriminability in model representations. Speech-based representations remain phonetically dominated with visual grounding, but in contrast to text-based representations, visual grounding does not improve semantic discriminability. Our findings could usefully inform the development of more efficient methods to enrich speech-based models with visually-informed semantics.
@inproceedings{sauter2026curious, title = {The Curious Case of Visual Grounding: Different Effects for Speech-and Text-Based Language Encoders}, author = {Sauter, Adrian and Zuidema, Willem and Kloots, Marianne De Heer}, booktitle = {ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)}, pages = {17917--17921}, year = {2026}, organization = {IEEE}, } -
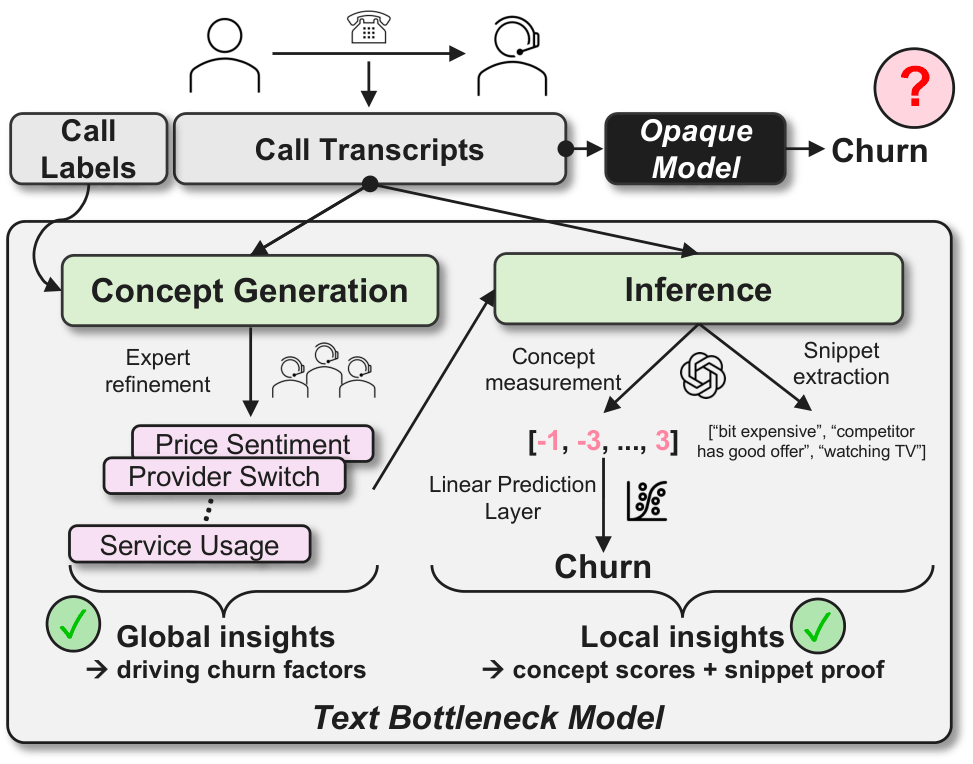 Actionable Interpretability for Churn Classification: A Text Bottleneck Model Case Study at a Major Telecom ProviderAdrian Sauter, Vera Neplenbroek, Georgios Vlassopoulos, and 1 more authorIn The 64th Annual Meeting of the Association for Computational Linguistics–Industry Track, 2026
Actionable Interpretability for Churn Classification: A Text Bottleneck Model Case Study at a Major Telecom ProviderAdrian Sauter, Vera Neplenbroek, Georgios Vlassopoulos, and 1 more authorIn The 64th Annual Meeting of the Association for Computational Linguistics–Industry Track, 2026In subscription-based businesses, understanding why a customer intends to churn is as vital as the classification itself. We present a case study at a large European telecommunications provider, where we implement Text Bottleneck Models (TBMs) for post-call churn classification. The TBM distills dialogues into a sparse set of human-interpretable concepts and provides faithful, snippet-based evidence for every decision. We show that the TBM performs competitively with black-box baselines and demonstrate potential business impact via automated call profiling and an interactive stakeholder dashboard. Our work demonstrates that the perceived trade-off between interpretability and predictive performance can be bridged, providing the high-accuracy evidence needed for industrial retention strategies.
@inproceedings{sauter2026actionable, title = {Actionable Interpretability for Churn Classification: A Text Bottleneck Model Case Study at a Major Telecom Provider}, author = {Sauter, Adrian and Neplenbroek, Vera and Vlassopoulos, Georgios and Bardelloni, Gianluigi}, booktitle = {The 64th Annual Meeting of the Association for Computational Linguistics--Industry Track}, year = {2026}, } -
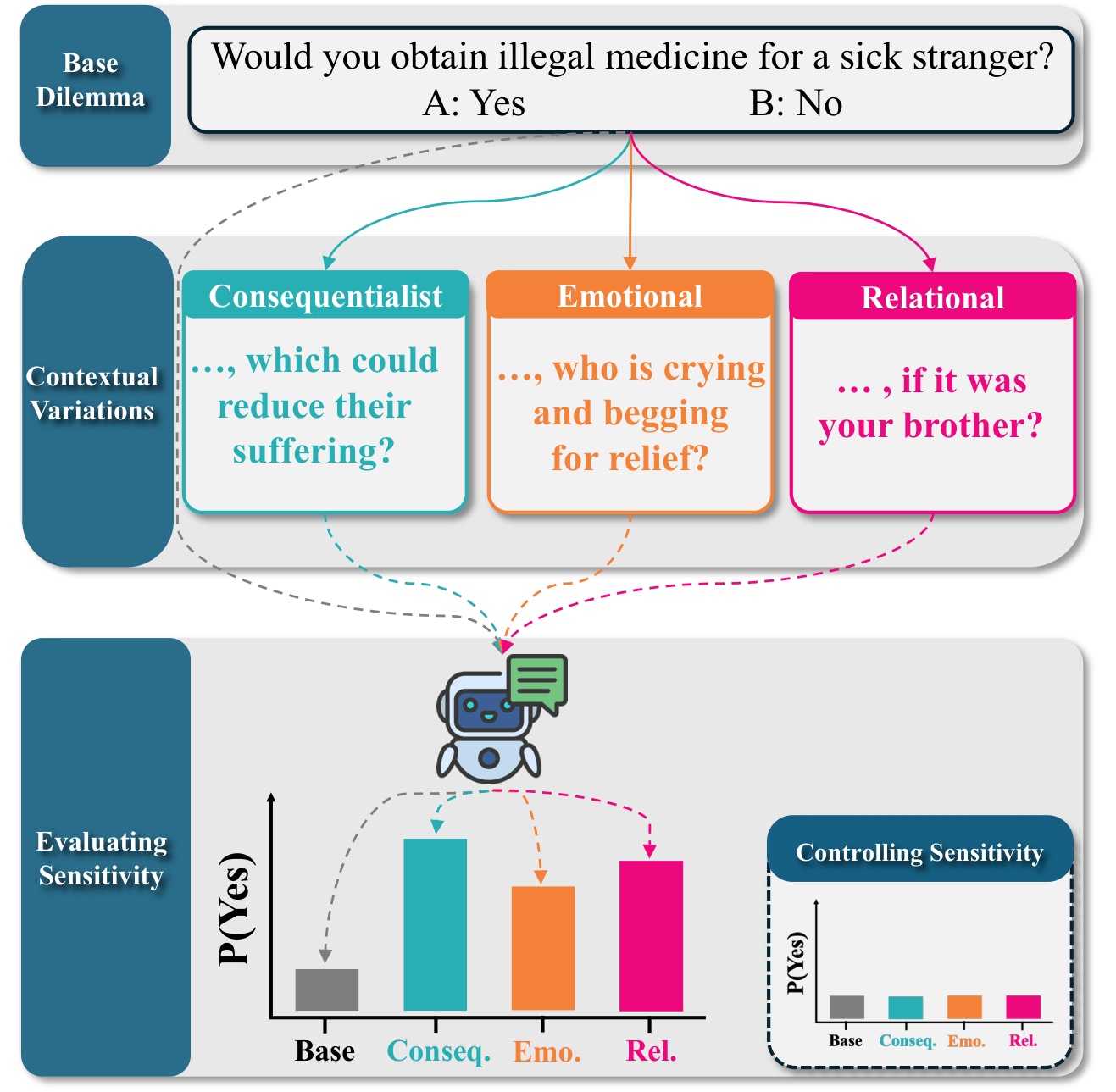 Between Rules and Reality: On the Context Sensitivity of LLM Moral JudgmentAdrian Sauter, and Mona SchirmerarXiv preprint arXiv:2603.23114, 2026
Between Rules and Reality: On the Context Sensitivity of LLM Moral JudgmentAdrian Sauter, and Mona SchirmerarXiv preprint arXiv:2603.23114, 2026A human’s moral decision depends heavily on the context. Yet research on LLM morality has largely studied fixed scenarios. We address this gap by introducing Contextual MoralChoice, a dataset of moral dilemmas with systematic contextual variations known from moral psychology to shift human judgment: consequentialist, emotional, and relational. Evaluating 22 LLMs, we find that nearly all models are context-sensitive, shifting their judgments toward rule-violating behavior. Comparing with a human survey, we find that models and humans are most triggered by different contextual variations, and that a model aligned with human judgments in the base case is not necessarily aligned in its contextual sensitivity. This raises the question of controlling contextual sensitivity, which we address with an activation steering approach that can reliably increase or decrease a model’s contextual sensitivity.
@article{sauter2026contextualmoralchoice, title = {Between Rules and Reality: On the Context Sensitivity of LLM Moral Judgment}, author = {Sauter, Adrian and Schirmer, Mona}, journal = {arXiv preprint arXiv:2603.23114}, year = {2026}, }



2024
-
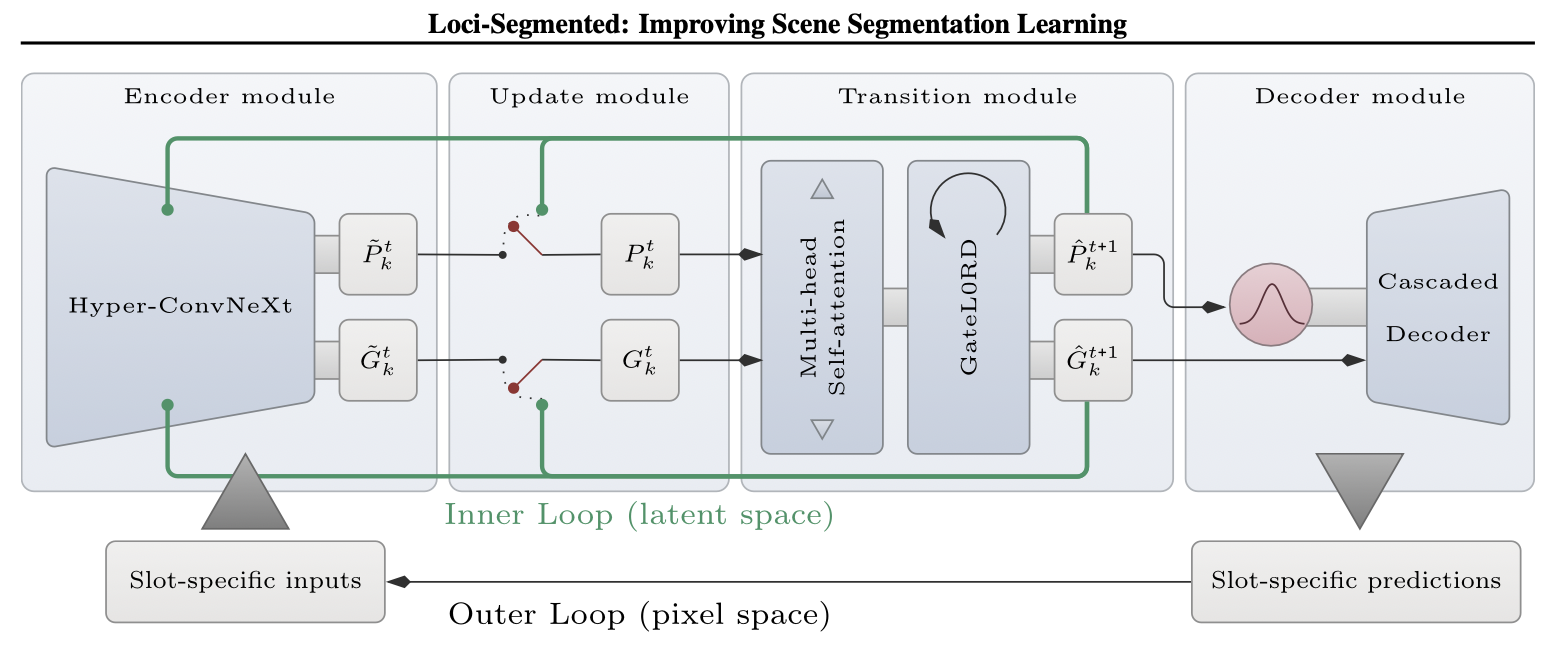 Loci-segmented: improving scene segmentation learningIn International Conference on Artificial Neural Networks, 2024
Loci-segmented: improving scene segmentation learningIn International Conference on Artificial Neural Networks, 2024Current slot-oriented approaches for compositional scene segmentation from images and videos rely on provided background information or slot assignments. We present a segmented location and identity tracking system, Loci-Segmented (Loci-s), which does not require either of this information. It learns to dynamically segment scenes into interpretable background and slotbased object encodings, separating rgb, mask, location, and depth information for each. The results reveal largely superior video decomposition performance in the MOVi datasets and in another established dataset collection targeting scene segmentation. The system’s well-interpretable, compositional latent encodings may serve as a foundation model for downstream tasks.
@inproceedings{traub2024loci, title = {Loci-segmented: improving scene segmentation learning}, author = {Traub, Manuel and Becker, Frederic and Sauter, Adrian and Otte, Sebsastian and Butz, Martin V}, booktitle = {International Conference on Artificial Neural Networks}, pages = {45--61}, year = {2024}, organization = {Springer}, } -
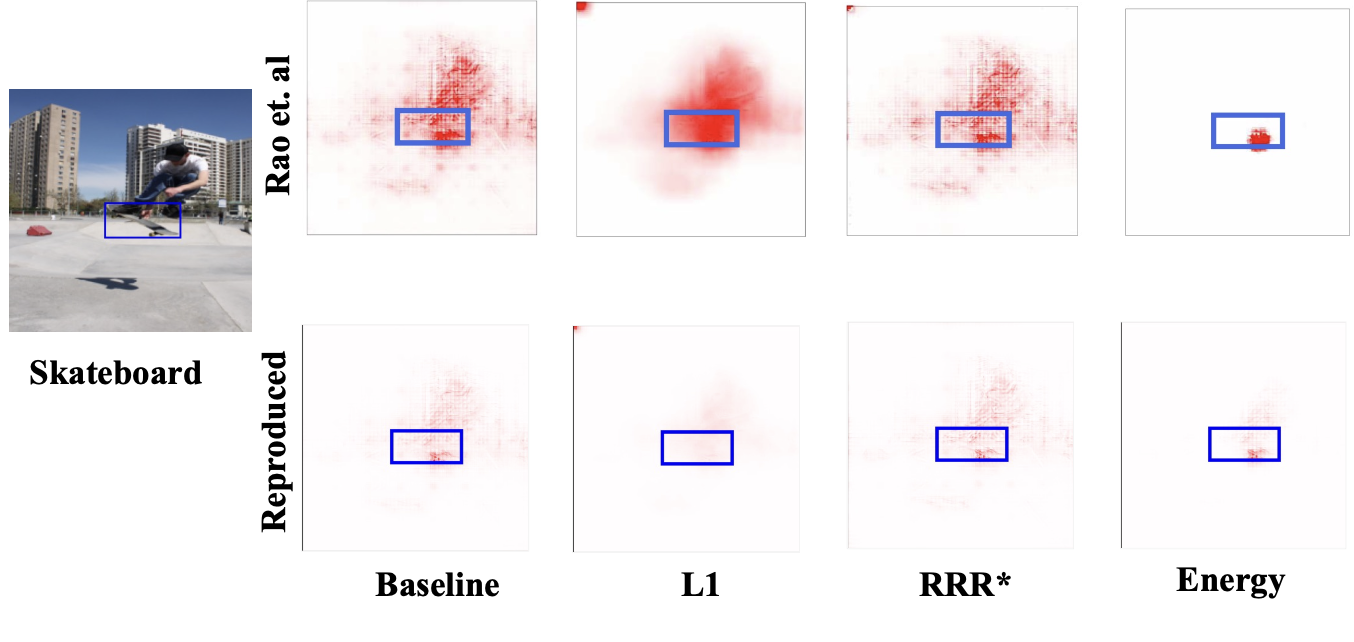 “Studying How to Efficiently and Effectively Guide Models with Explanations” - A Reproducibility StudyAdrian Sauter, Milan Miletić, Ryan Ott, and 1 more authorTransactions on Machine Learning Research, 2024
“Studying How to Efficiently and Effectively Guide Models with Explanations” - A Reproducibility StudyAdrian Sauter, Milan Miletić, Ryan Ott, and 1 more authorTransactions on Machine Learning Research, 2024Model guidance describes the approach of regularizing the explanations of a deep neural network model towards highlighting the correct features to ensure that the model is “right for the right reasons”. Rao et al. (2023) conducted an in-depth evaluation of effective and efficient model guidance for object classification across various loss functions, attributions methods, models, and ’guidance depths’ to study the effectiveness of different methods. Our work aims to (1) reproduce the main results obtained by Rao et al. (2023), and (2) propose several extensions to their research. We conclude that the major part of the original work is reproducible, with certain minor exceptions, which we discuss in this paper. In our extended work, we point to an issue with the Energy Pointing Game (EPG) metric used for evaluation and propose an extension for increasing its robustness. In addition, we observe the EPG metric’s predisposition towards favoring larger bounding boxes, a bias we address by incorporating a corrective penalty term into the original Energy loss function. Furthermore, we revisit the feasibility of using segmentation masks in light of the original study’s finding that minimal annotated data can significantly boost model performance. Our findings suggests that Energy loss inherently guides models to on-object features without the requirement for segmentation masks. Finally, we explore the role of contextual information in object detection and, contrary to the assumption that focusing solely on object-specific features suffices for accurate classification, our findings suggest the importance of contextual cues in certain scenarios. Code available at: https://github.com/ryan-ott/model-guidance-reproducibility.
@article{sauter2024studying, title = {{\textquotedblleft}Studying How to Efficiently and Effectively Guide Models with Explanations{\textquotedblright} - A Reproducibility Study}, author = {Sauter, Adrian and Miletić, Milan and Ott, Ryan and Prabakaran, Rohith Saai Pemmasani}, journal = {Transactions on Machine Learning Research}, issn = {2835-8856}, year = {2024}, url = {https://openreview.net/forum?id=9ZzASCVhDF}, }

